Riscv_xv6
RVOS
汇编器AS 反汇编
riscv64-unknown-elf-objdump -D -b binary -m riscv test.bin > disassembly_out
1. 基础
1.1 GCC的使用
1.2 GDB的使用
1. gdbinit文件
使用gdbinit文件作为默认配置文件,帮你自动输入一些命令:
set disassemble-next-line on
target remote localhost:1234
layout regs
b _start
要使当前的gdbinit文件生效需要将~/.gdbinit配置文件中加上当前文件的路径,否则gdbinit文件不能生效:
add-auto-load-safe-path /home/songyj/embedded_proj/xv6-riscv/.gdbinit add-auto-load-safe-path /home/songyj/embedded_proj/rk3399/.gdbinit
启动gdb并使用当前的配置文件:
gdb tui ./rk3399.elf -x ./.gdbinit
2. 具体命令
examine: inspect memory contents
x/nfu addr
n: count f: format u: unit size
只观察thread 1到达断点
break _start thread 1
Debug Multithread Program with GDB
在某个地址打断点
b *0x80000000
后面程序会运行到用户空间,想debug用户空间的程序必须要重新加载符号表!
file ./user/first_test.out
调试用户空间的程序也很重要:debug用户程序
3. 更多
1.3 Makefile
自动化变量 Automatic varibles
- $@ 指代生成的目标文件 target filename
- $< 指代第一材料文件 1st prerequisit filename
- $^ 指代所有的材料文件
1.4 Linkerscript
链接的代码段最前面的一定要自己指定好 刚才重写了sbi的链接脚本 去掉了之前指定sbi_boot.s代码段在最前面的标号 直接所有用text表示结果gdb调试进不去 发现本来sbi_boot的代码段链接在sbi_main.c代码段后面去了
1. ALIGN()
2. 在源文件中使用链接脚本当中的变量
_s_text = 0x80000000;
在c源文件中访问 _s_text
extern unsigned char _s_text;
unsigned char *value_in_var;
value_in_var = &_s_text;
可以将这个特殊的变量 _s_text 看成是一个空值的变量,他在symbol table上的对应的地址是0x80000000 我们访问一个变量的地址用& 参考
1.5 汇编和C
1. 汇编
大端小端 big endian/little endian 讲的是字节不是位
128 64 32 16 8 4 2 1 is big endian,big-end comes first
1 2 4 8 16 32 64 128 is little endian,little-end comes first 低位字节在前面
字节对齐 align
#字节对齐
.align size-log-2
存储指令
#存储指令
#sd rs1, offset(rs2)
#往0x80000000上写0
li a0, 0x80000000
sd zero, (a0)
call j jr
call和j指令需要特别注意,call是一条伪指令相当于把pc+4放入ra
#函数调用指令 call
call add_ab
#等价于
#ra <-- pc+4
#j add_ab
#函数返回指令 ret
ret
#等价于
#pc <-- ra
jr用于跳转寄存器里面存的地址
AUIPC LUI
Add Upper Immediate to Program Counter Load Upper Immediate
#将立即数带符号左移12bits加到PC
auipc a5, 0x02
#将立即数带符号左移12bits
lui a5, 0x02
2. C语法
函数指针
//func_ptr_name是一个指向函数的指针,这个函数有两个int参数,返回的值是int
int (*func_ptr_name)(int, int);
//cast
//some_ptr是一个函数指针
(int (*)(int, int))some_ptr;
//函数指针数组
//类似[SYS_fork]是索引
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
};
//调用
syscalls[num]();
3. riscv的寄存器
General reg
通用寄存器有别名和特殊用途
| 通用寄存器 | 别名 | 特殊用途 |
|---|---|---|
| x0 | zero | 全零寄存器 |
| x1 | ra | 函数返回地址 |
| x2 | sp | stack ptr |
| x3 | gp | globle ptr |
| x5~x7, x28~x31 | t0~t2, t3~t6 | tempories Callee可能会使用不保证在函数调用过程中不变 |
| x8~x9, x18~x27 | s0~s1, s2~s11 | saved Callee如果要使用必须在stack中备份,退出时恢复 |
| x10~x11 | a0~a1 | argument 参数寄存器 函数返回值也在里面 |
| x12~x17 | a2~a7 | argument 参数寄存器 |
CSR
| CSR | 用途 |
|---|---|
| msratch | m模式下上下文数据指针 |
| mcause | m模式异常中断 |
| satp | s模式页表指针 |
| scause | s模式异常中断 |
| sepc | s模式异常中断处理之后返回的地址 |
| stvec | s模式异常中断进入的地址 |
Stack versus Heap
都存在于RAM当中
每一个线程都有自己的stack 所有的线程共享同一个heap
stack是确定的长度不能改变 heap的长度可以改变 如果需要heap存一个新的变量但是没有足够的空间 操作系统可以分配新的空间给到heap
// 分配在数据段 如果等于0在bss 如果不等于0在data
int someGlobalVariable;
// 分配在数据段
static int someStaticVariable;
void MyFunction(int someArgument) {
// 分配在数据段
static int someLocalStaticVariable;
// 分配在栈上
int someLocalVariable;
int* someDynamicVariable;
// 分配在堆上
someDynamicVariable = new int;
delete someDynamicVariable;
return;
}
// Note that someGlobalVariable, someStaticVariable and
// someLocalStaticVariable continue to exist, and are not
// deallocated until the program exits.
stack trace(栈回溯)
当我们出现异常时,os通常可以打印出一系列函数调用的信息,这是怎么做到的?
编译器使能frame pointer之后(-fno-omit-frame-pointer),每次进入函数会有如下汇编代码生成:
#stack腾出16byte的空间
#先放函数返回地址ra(8byte),再放fp(8byte)
#此时的fp存储的是上一个函数分配的stack空间的起始地址
#更新fp=当前函数被分配的stack空间起始地址
addi sp, sp, -16
sd ra, 8(sp)
sd fp, 0(sp)
addi fp, sp, 16
stack是从高地址向低地址生长,所以在用指针去访问存储在stack当中的结构体时要注意
//将上述fp和ra看成一个结构体
//因为stack和地址是反的 从地址的角度来看低地址放的是fp高地址放的是ra
struct stack_frame
{
unsigned long sf_fp;
unsigned long sf_ra;
};
void back_trace()
{
//取得当前的fp值
//__builtin_frame_address gcc自带特性
unsigned long cur_fp = __builtin_frame_address(0);
unsigned long pc;
//通过结构体指针去访问stack frame
struct stack_frame *sf_ptr = cur_fp - 16;
//循环条件在代码段中
while(sf_ptr->sf_fp > &_stext)
{
//返回地址减去4就是程序的调用地址
pc = sf_ptr->sf_ra - 4;
printf("pc: %p\n", pc);
//指向下一个stack frame
sf_ptr = sf_ptr->sf_fp - 16;
}
}
思考:为什么计算机的pc每次都是+4而不是1?
指令长度4byte
1.5.2 static inline
在异常处理或者中断的时候经常见到调用一个函数然后然后找到这个函数发现他是static inline …里面只有一条汇编指令 感觉有点看不懂
inline关键字什么意思? 函数定义前面加inline表示这是一个Inline Function Inline Function are those function whose definitions are small and be substituted at the place where its function call is happened. 这种函数一般很短,转换成汇编指令可能只有一条指令。如果将它写成一个普通的函数跳转过去执行 可能跳转执行然后再返回的一串指令比这条指令本身长很多,这样执行效率会降低。
inline提示编译器可以把这条内联函数直接编译到调用他的代码出处,这样无需跳转返回的一系列指令 但是这也只是一条hint 编译器不一定会inline这个函数
为什么要前面加上static呢? 如果只有前面的inline对于GCC来说会报错
#include <stdio.h>
inline int add_two(int a, int b)
{
return a+b;
}
int main()
{
int ret;
ret = add_two(1, 3);
printf("output : %d", ret);
return 0;
}
/usr/bin/ld: /tmp/ccy8plLQ.o: in function `main':
try_inline.c:(.text+0x17): undefined reference to `add_two'
collect2: error: ld returned 1 exit status
前面说到inline只是一条建议 建议编译器可以内联 但是编译器不一定会采纳 所以这里实际的意思是告诉编译器This is an alternative function to use if you want to inline this function
在rk3399中读取pc寄存器的值只使用static inline并没有内联还是跳转到了函数的位置:

内联汇编之后之前的r_pc()函数就消失了,所以程序的地址也发生了改变:

加上static则可以避免这个错误,让编译器把这个函数当作internal linkage
If you don’t put static there, you’re defining an inline function with external linkage without instantiating an external definition.
如何强制inline一个函数呢?
GCC提供了attribute((always_inline))
static inline __attribute__((always_inline)) unsigned long r_pc()
{
unsigned long x;
asm volatile(
"adr %0, ."
: "=r" (x)
:
:
);
return x;
}
1.5.3 UART输出字符串的写法对比
void uart_send_string(char *str)
{
char *string_ptr = str;
while(*string_ptr != '\0')
{
uart_send_char(*string_ptr);
string_ptr++;
}
}
void uart_puts(char *s)
{
while (*s) {
uart_putc(*s++);
}
}
涉及到 i++ ++i 的区别 i++先返回值后inc ++i先inc后返回值 ++i是加一之后的值 i++ 是加一之前的值
1.5.4 printf的实现
实现完串口的输出,发现rvos和xv6都还实现了printf函数,这个看起来好像比较简单先实现一下这个文件
可变参数函数 (variadic function in c)
此处涉及到的宏定义暂不深究 va_list va_start() va_arg() va_end()
#include <stdarg.h>
//...表示数量不定的参数
void printf(char *format, ...)
{
va_list args;
va_start(args, format); //va_start的第二个参数是...之前的参数,即最后一个确定的参数
for(; *format!=0;)
{
//va_arg()执行一次会返回一个参数值,然后指到下一个参数
//解析格式字符串的%标记以及后面的字符来确定打印类型
if(*fmt == '%')
{
switch(*(++fmt))
{
case 'd':
{
va_arg(args, 可变参数类型(int,char,float ...));
//分别根据单独的数据类型输出
break;
}
case 'x':
{
va_arg(args, 可变参数类型(int,char,float ...));
break;
}
case 'p':
{
va_arg(args, 可变参数类型(int,char,float ...));
break;
}
default:
{
//处理特殊情况
break;
}
//指向下一个字符
format++;
}
}
else
{
uart_send_char(*format++);
}
}
va_end(args);
}
1.5.5 杂
固定串口设备的串口号并设置权限
每次sudo chmod太麻烦,用udev规则自动完成设置
lsusb 查看usb设备信息
sudo vim /etc/udev/rules.d/99-serial-ports.rules #设置udev规则表 默认两位数字开头 越小优先级越高
添加 SUBSYSTEM=="tty", ATTRS{idVendor}=="xxxx", ATTRS{idProduct}=="yyyy", MODE="0666"
sudo udevadm control --reload-rules
2. Trap(异常的处理)
调riscv板子的时候经常看到opensbi,但是又不知道opensbi干嘛的。只知道opensbi引导uboot,uboot再引导内核
2.1 sbi服务
为运行在S模式的操作系统提供特权服务接口,sbi固件是运行在M模式的权限最高。 为处于低级别的程序提供访问重要硬件的接口
- 架构图
2.2 sbi系统调用是异常的一种
mcause寄存器有两个字段分别表示异常类型和中断类型
| Interrupt | Exception Code |
|---|---|
| 1表示中断 0表示异常 | 具体的中断或者异常类型 |
其中9号异常表示来自S模式的系统调用,通俗来说就是运行在S模式的操作系统通过上边提到的sbi服务接口完成了一些只能在M模式下面做的事情。
我们只需要顺清楚这里面的一种服务就可以知道他整个机制是如何运行的。
2.3 异常过程(sbi系统调用为例)
sbi服务是软件产生的异常,那么如何产生呢?
2.3.1 ECALL指令
a0~a5存放形参 a7存放系统调用号,区分是哪个Syscall
ecall会提升特权模式 在s mode下使用会提升到m mode 并且PC跳转到mtvec指向的地址
#define SBI_CALL(which, arg0, arg1, arg2) ({ \
register unsigned long a0 asm ("a0") = (unsigned long)(arg0); \
register unsigned long a1 asm ("a1") = (unsigned long)(arg1); \
register unsigned long a2 asm ("a2") = (unsigned long)(arg2); \
register unsigned long a7 asm ("a7") = (unsigned long)(which); \
asm volatile ("ecall" \
: "+r" (a0) \
: "r" (a1), "r" (a2), "r" (a7) \
: "memory"); \
a0; \
})
在调用之前首先需要在sbi程序中设置好跳转地址。
void sbi_trap_init()
{
w_mtvec(sbi_exception_vec);
w_mie(0);
}
根据sbi_trap_init()代码,程序在执行ecall之后会跳转到sbi_exception_vec()这个函数这里,这是一个统一的入口函数,微机原理里面就学过,进入中断需要保存现场,这里ecall跳转的sbi_exception_vec()函数其实就算是中断处理函数。
- 保存上下文(context)
- 切换sp
- 根据具体的系统调用功能执行相应的函数
- 恢复上下文
- 切换sp
- 根据mepc返回继续执行
2.3.2 USER模式下系统调用流程示意图
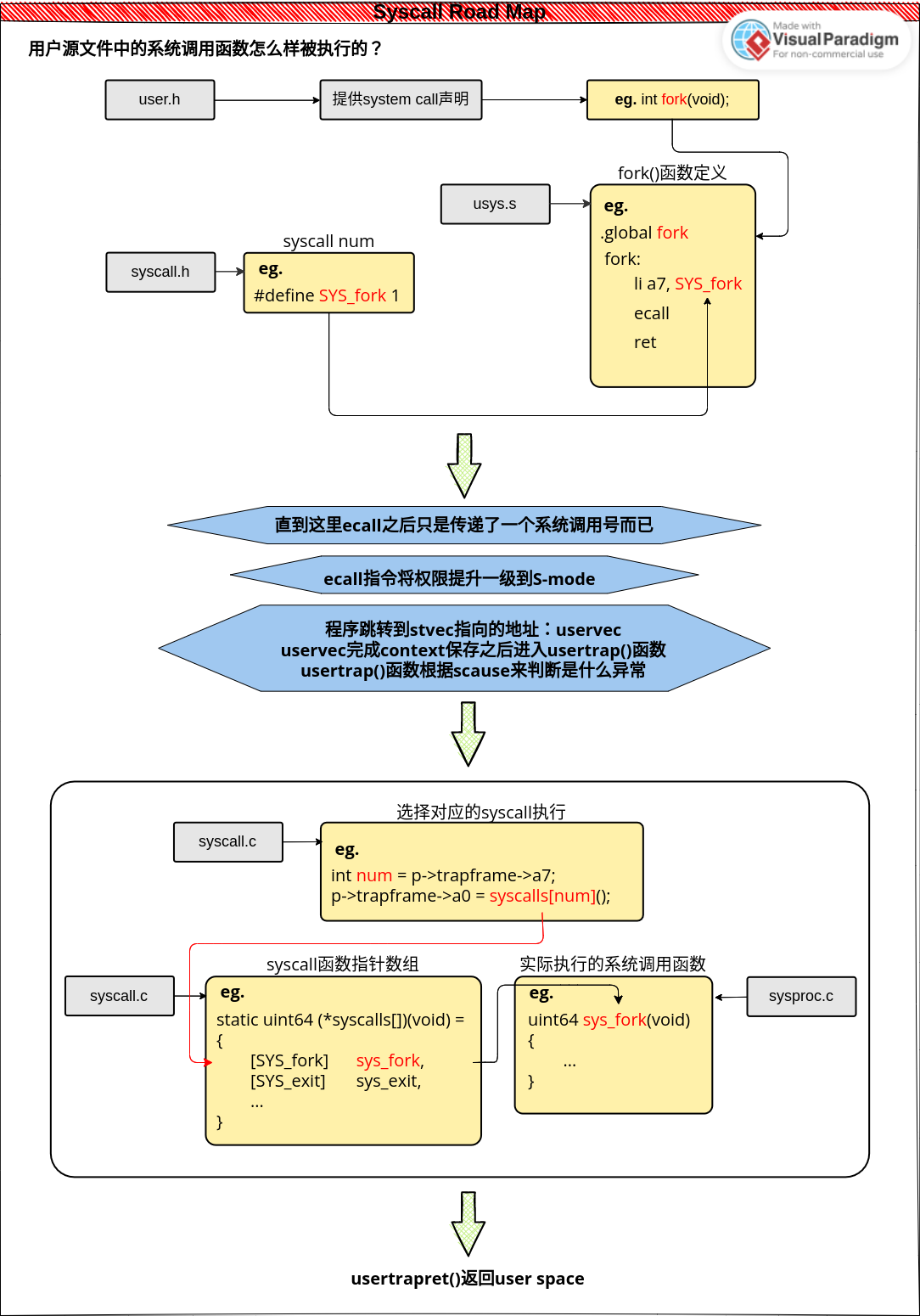
2.3.3 系统调用中传递参数
- kernel调用sbi的服务 kernel中使用ecall
有的系统调用有参数,比如最简单的sleep(),sleep()的参数是休眠的时钟周期比如sleep(1000),那在用户空间里面使用的参数怎么样传递到内核中去的呢?
根据riscv的函数调用标准,参数是存放在a0~a7当中的,这里sleep的参数休眠周期就会存放在a0中,回顾ecall指令发生时,第一步保存上下文将所有的寄存器全部放在trapframe当中,所以当执行到具体的syscall函数时:
argraw(int n)
{
struct proc *p = myproc();
switch (n)
{
case 0:
return p->trapframe->a0;
case 1:
return p->trapframe->a1;
case 2:
return p->trapframe->a2;
case 3:
return p->trapframe->a3;
case 4:
return p->trapframe->a4;
case 5:
return p->trapframe->a5;
}
panic("argraw");
return -1;
}
sys_sleep()
{
int time_interval;
...
time_interval = argraw(n);
...
}
虽然sys_sleep()本身没有参数,但是函数在一开始就通过读取trapframe的方式,获得了用户空间中的参数。
2.4 注意
在调试s模式的异常时,写好了s模式下的中断处理函数但是没有trap到s模式的中断处理函数,直接到了m模式的中断处理函数。重新看书才发现:
委托异常与中断: 中断和异常触发之后默认M模式下进行处理,我们通常吧常用的异常和中断委托给S模式,这样才会跳转到S模式的异常向量表中去。
xv6中断过程
timervec 1.在CMP填入新值 2.置位SSIP
中断分类
软件中断 定时器中断 外部中断 调试中断
0x0d号中断 一般都是页表映射没设置好 导致找不到页面
2.5 trapframe trampoline
swtch保存上下文和uservec保存上下文为什么不一样? swtch只保存了ra sp + s系列寄存器 uservec保存了所有
trapframe用于保存用户进程的上下文,kernel进程的上下文则在自己的stack中保存,所以kernel进程是没有trapframe的。
2.6 xv6 roadmap
软件中断还有问题?scheduler如何切换回去 scheduler如何到usertrap
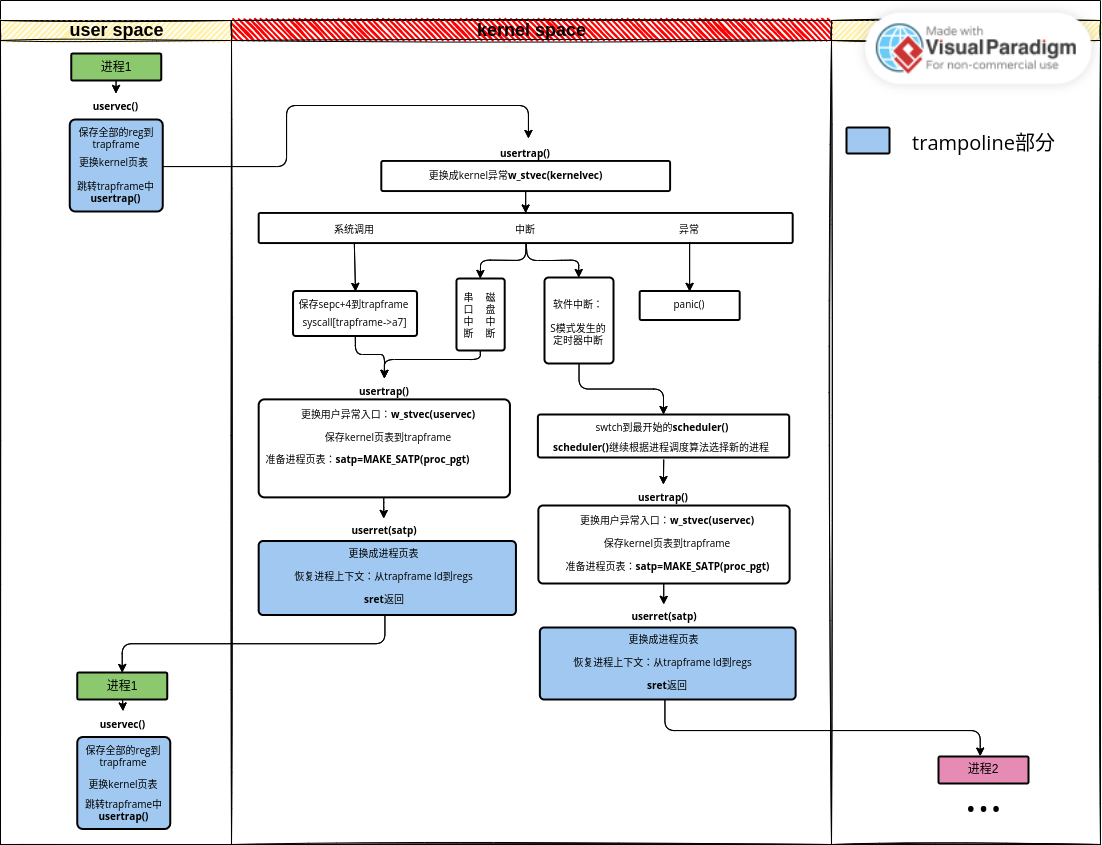
2.7 sleep()和wakeup()
2.8 问题记录
- 在测试串口中断时,串口中断标志位清除不了 最开始没有加入串口接收终端,但是但后期发现必须要有一个shell来执行命令才能运行更多的user程序测试多进程的一些东西。最后突然发现是没有读取接收数据缓存寄存器。。。
3. Page Table
3.1 为什么要有虚拟地址?
试想有个一64K大小的程序需要运行在ram只有32K大小的电脑中,ram没有办法装入整个程序,我们应当如何让这个程序跑起来? 程序当中的内容不是所有的都对当前程序的正常运作有关系,我们可以将程序分成固定大小的page例如4K,那么64K程序可以分成16个page,分别标号0到15。同样的,我们将ram也分成4k大小的page并称为page frame,得到page frame 0~7。按照程序的需求将page和page frame对应起来,将需要用的page和page frame对应起来,即把需要的page里面的内容加载到对应的page frame处。
这样程序就跑起来了。但是64K大小的程序实际上只有32K的内容被加载到RAM当中,万一运行到没有加载的page的指令怎么办?此时这条指令的地址(虚拟地址)被传到MMU,MMU通过page号段查找到对应的PTE,发现根据PTE标志位段显示,这个地址所处的page没有被映射到page frame,触发page fault异常,异常处理会取消一对对应关系,重新将这个page映射一个page frame上,退出异常后再次寻址可以继续执行。
3.2 虚拟地址组成
sv39分页机制
| 最高25bits保留 | 27bits | 12bits |
|---|---|---|
| 保留 | page号 | offset |
12位的offset用于寻址4K的地址 27位page号n说明这个地址位于第n个page,同时page table的 第n条目(PTE) 存储了page n的映射关系
PTE (page table entry)
| PPN (physical page number) page frame号 | 标志位 (eg.映射没映射) |
|---|---|
| 44bits | 10bits |
44bits的page frame和12bits的offset可以在RAM上寻址。
3.3 多级页表
按照4k的分页方法,32位机器:
2^32 /4/1024=2^20=1048576
我们需要有1048576条PTE,这么大的页表放在RAM中是不可接受的,64位更多。
3.4 TLB(Translation Lookaside Buffers)
Most programs tend to make a large number of references to a small number of pages, and not the other way around.
3.5 页表创建流程
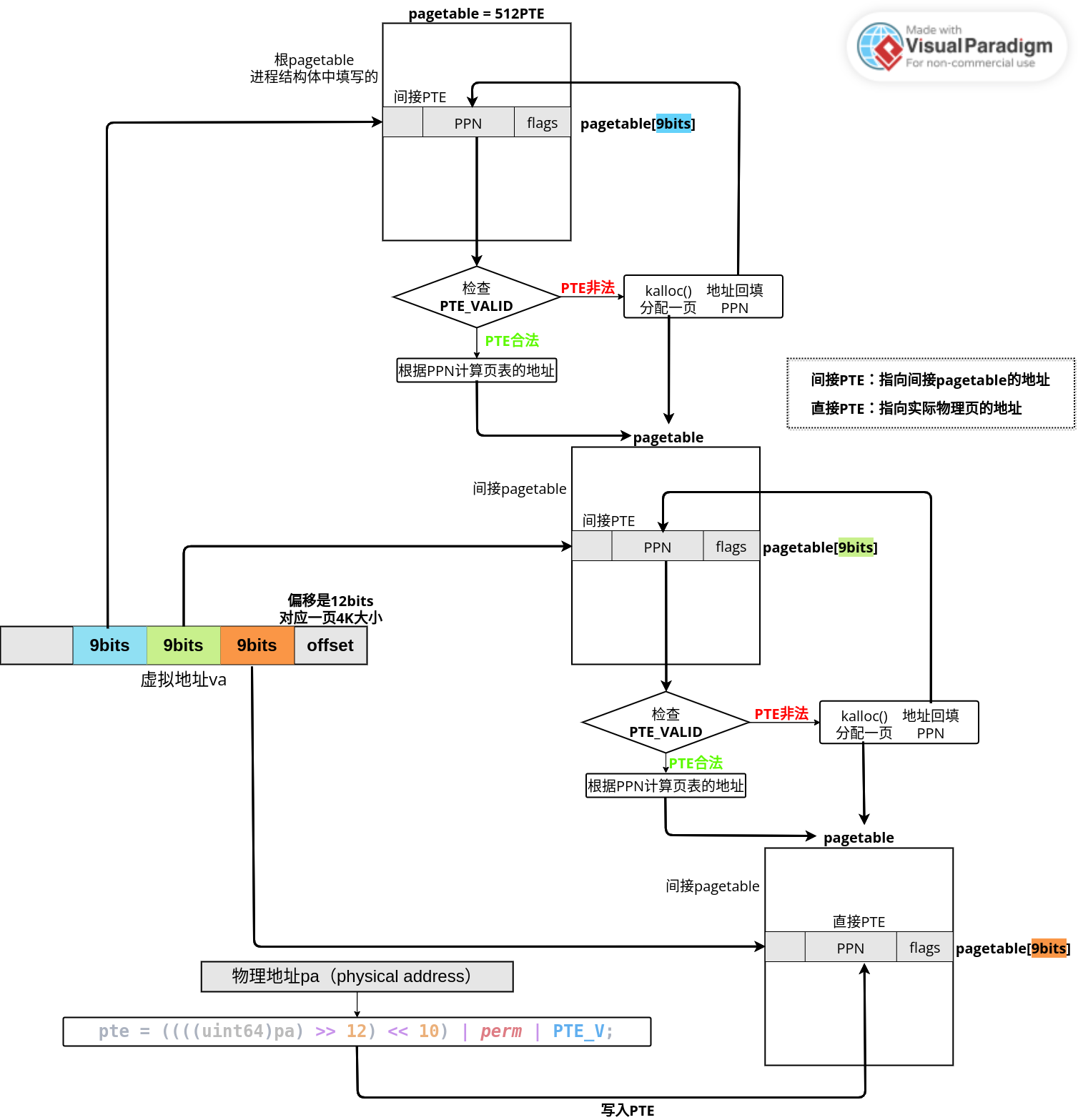
- 分配4K空间,用于存放pagetable 4096byte/8byte=512 有512条PTE 在linker.ld当中给pagetable直接分配4k空间,放在数据段最后面。
...
_sdata = .;
.data :
{
*(.data)
}
. = ALIGN(4096);
_pgt_start = .;
. += 4096;
_edata = .;
...
//定义pgt_t是指向unsigned int的指针
typedef unsigned long *pgt_t;
typedef unsigned long pte_t;
PTE是最末一级页表的一个条目,这些页表都可以看作是一个数组,每个pte都是一个元素: unsigned long pagetable[512];
//walk函数返回指向具体页表项(PTE)的指针
//walk函数可以让我们走到最末尾的元素上去
pte_t *walk(pgt_t pagetable, unsigned long va, int alloc);
一开始我们只有虚拟地址假设是0x80200000以及一个根页表也就是上面linkerscript中分配的空间
extern unsigned long _pgt_start[];
pgt_t pagetable = _pgt_start[];
unsigned long va = 0x80200000;
pte_t *walk(pagetable, va, 1);
虚拟地址示意:
| 最高25bits保留 | 9bits | 9bits | 9bits | 12bits |
|---|---|---|---|---|
| 保留 | 2级 | 1级 | 0级 | offset |
根据2级目录寻找1级目录的位置,根据1级目录寻找0级目录的位置,而0级目录里面存放的就是我们真正的PTE
//伪代码
9bits = va>>12>>(9*level) & 0x1FF;
//marco
#define MASK 0x1FF
#define OFFSET 12
#define GET_NINE_BITS(va, level) ((va>>OFFSET>>(9*level)) & MASK)
若只考虑页表已经建立好,我们只来寻找最末PTE:
pte_t *walk(pgt_t pagetable, unsigned long va, int alloc)
{
pgt_t pgt_ptr;
pte *pte_ptr;
for(int level=2; level>0; level--)
{
pgt_ptr = &pagetable[GET_NINE_BITS(va, level)];
//如果这个条目是valid
if(*pgt_ptr | PG_V)
{
//取出存放的物理页号PPN 无符号右移10位 最末10位是flags
//根据PPN得到下一个页表的首地址 左移12位
pgt_ptr = ((unsigned long)(*pgt_ptr))>>10<<12;
}
}
pte_ptr = &pagetable[GET_NINE_BITS(va, 0)]
return pte_ptr;
}
加入页表没有建立好的情况
pte_t *walk(pgt_t pagetable, unsigned long va, int alloc)
{
pgt_t pgt_ptr;
for(int level=2; level>0; level--)
{
pgt_ptr = &pagetable[GET_NINE_BITS(va, level)];
//如果这个条目是valid
if(*pgt_ptr | PTE_V)
{
//取出存放的物理页号PPN 无符号右移10位 最末10位是flags
//根据PPN得到下一个页表的首地址 左移12位
pagetable = ((unsigned long)(*pgt_ptr))>>10<<12;
}
//这个条目不存在
else
{
//允许分配且有内存可分配
if(alloc || (pagetable=kalloc())==1)
{
memset(pagetable, 0, 4096);
//回填
*pte_ptr = (((unsigned long)pagetable)>>12<<10) | PTE_V;
}
else
{
return 0;
}
}
}
pte_ptr = &pagetable[GET_NINE_BITS(va, 0)];
return pte_ptr;
}
3.6 进程的Pagetable
xv6采取的方式是内核有一个kernel pagetable,每一个进程有自己的process pagetable
Having a separate page table for each process is necessary for process isolation as they should not be allowed to stomp on each others memory.
每个进程都有自己的stack,如何检测到stcakoverflow呢? 我们注意到xv6每个stack之间都有guardian page,超出会访问guardian page造成page fault
不同的进程可以使用相同的虚拟地址,但经过各自page table映射到不同的物理地址,彼此不会干扰。
3.7 Address Space
Like those other systems, upon a context switch, the user portion of the currently-running address space changes; the kernel portion is the same across processes.
3.8 问题
- 在加入新的文件之后,页表不能正确切换,有些已经建立的页表映射没有成功显示 最后定位到新加入文件bss段的一个变量,发现这个变量长度超过一个值就不能建立完整的页表映射,但是很说不通,最后发现linkerscript里面将根页表的起始地址和bss段重合了,在没加入这个新文件之前恰好没有影响到页表的建立。
4. 进程 (Process)
4.1 启动第一个进程
目前为止,内核的页表kernel pagetable已经设置好了,映射了整个DDR,即从0x80000000开始的128M地址空间。还映射了UART的位置0x10000000,大小为0x1000。trap的流程也走通了,m模式委托异常和中断给s模式,可以实现一些简单系统调用,例如打印等。但是我们其实现在仍然处于S模式,要知道用户程序肯定是在u模式当中运行的。接下来就应该从kernel启动一个init进程,而且这个init进程应该运行在u模式,并且这个用户程序可以通过系统调用或者中断的形式trap到s模式进行处理,处理之后还要返回到用户程序继续执行。
kernel pagetable配置的空间是kernel address space,用户进程需要的是process address space,进程不能够看到内核的代码,这需要设置一个新的进程页表。
而从kernel启动进程就需要我们提前设置user pagetable,随之而来的问题就是
sfence.vma zero zero
csrw satp a0
sfence.vma zero zero
执行完写satp寄存器之后,页表就会立刻更改,kernel space和process space如果没有把这段代码映射在相同的地方,执行就会出错cannot access
这就是trampoline代码的位置,xv6巧妙的利用了这段代码,从内核启动第一个用户进程不久相当于用户trap到内核,处理完成后再从内核退到用户进程吗?这一过程需要做几件事情才能完成进程的顺利启动:
- 装载用户pagetable
- 保存当前kernel的context
- 装载用户程序的context
完成上面的事情之后只需要一条
sret
pc就会被硬件设置到sepc处,然后从pc开始运行。
接下来就完成一个init程序,这个程序只通过系统调用打印一个字符0。
参考xv6,发现有一段initcode[]是纯机器指令,这段initcode源码在xv6/user下面,调用了一个syscall exec,运行了xv6的shell。
#反汇编initcode.out得到initcode[]
#小段存放
riscv64-linux-gnu-objdump -d ./user/initcode.out
效仿xv6的做法:
.globl start
start:
li a7, 0x20
li a0, 0x30
ecall
loop:
j loop
这里的系统调用号是0x20可能不符合规范,但是测试一下整个流程应该可以不用在意。
//U模式trap处理函数
void user_trap()
{
int syscall_num = proc_list[0].trapframe->a7;
if(r_scause() == 8)
{
//proc_list[0].trapframe->a0 = 8;
proc_list[0].trapframe->a0 = syscall[syscall_num]();
}
else
{
printf("user_trap(): unexpected scause %p \n", r_scause());
printf(fault_info[r_scause()-0x8000000000000000].fault_name);
panic("panic/n");
}
proc_list[0].trapframe->epc = r_sepc() + 4;
user_trap_ret();
}
运行后可见打印了一个0

linux中的0号进程和1号进程
0号进程是管理进程调度的内核进程(即现在运行scheduler()的这个进程),1号进程是第一个用户进程,user_init()初始化的init进程。在linux中使用
ps -p 1
查看1号进程的信息显示是systemd,systemd是新一代的init,内核进程会寻找init程序去执行,没找到就会启动shell。
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");
4.2 进程之间的切换 scheduling
xv6当中进程之间的切换不是从一个进程切换到新的进程,而是从一个进程切换到内核再从内核切换到新的进程。

xv6设置了定时器中断,当定时器中断到来时触发yield(),随后调用sched(),在sched()之中调用swtch(),swtch中的操作会使得cpu重新回到内核进程,而内核进程之前已经执行到:
void scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
scheduler() 使用最简单的轮询算法完成新进程的选择,利用swtch() 进入新的进程。
第一个进程(打印0的那个进程)已经跑起来了,利用第一个进程把上述旧用户进程切换到内核scheduler进程,然后再切换到新内核进程的框架搭起来。相当于始终只调度一个用户进程:
//切换到内核进程
void back_to_kernel()
{
swtch(&proc_ptr->context, &kernel_ctxt.context);
}
//U模式trap处理函数
void user_trap()
{
int syscall_num = proc_ptr->trapframe->a7;
unsigned long trap_cause = r_scause();
if(trap_cause == 8)
{
proc_ptr->trapframe->a0 = syscall[syscall_num]();
proc_ptr->trapframe->epc = r_sepc() + 4;
}
//S模式软件中断
else if(trap_cause == 0x8000000000000001)
{
printf("soft interrupt from s mode %p \n", trap_cause);
w_sip(r_sip() & ~2);
back_to_kernel();
proc_ptr->trapframe->epc = r_sepc();
}
else
{
printf("user_trap(): unexpected scause %p \n", trap_cause);
printf(fault_info[r_scause()].fault_name);
panic("panic/n");
}
user_trap_ret();
}
指针proc_ptr始终指向当前运行的用户进程,kernel_ctxt是存储内核进程上下文的变量
//内核进程一直在调度函数中循环
void scheduler()
{
struct proc *nxt_proc_ptr = proc_ptr;
struct proc *kernel_ptr = &kernel_ctxt;
while(1)
{
proc_ptr = &proc_list[0];
for(int n=0; n<MAX_PROC; n++)
{
if(proc_ptr->state == RUNNABLE)
{
swtch(&kernel_ptr->context, &proc_ptr->context);
}
proc_ptr++;
}
}
}
scheduler() 遍历proc_list[MAX_PROC],找到RUNNABLE的程序执行,目前我们只有initcode程序是RUNNABLE,存放在proc_list[0]。
编译后运行反复打印:

2 进程之间的切换的一些细节
-
每个进程其实都有两个栈 一个内核栈一个用户栈,进程并不是所有的内容都在用户空间完成的:比如用户空间执行时遇到一个切换进程目的的定时器中断,此时程序会陷入到内核中,但是这时候还并没有发生进程的切换,程序仍然是当前的程序,只是现在在内核空间执行。
- 在user_trap_ret()一开始我们显式地关闭了中断
intr_off();但是在这之后没有调用以下指令显示地打开中断
intr_on();没有开启吗?如果没有开启的话依赖于定时中断的任务切换函数没有办法进入。但是实际上,任务切换依旧可以进行。其实中断是被隐式的打开了:
unsigned long x = r_sstatus(); x &= ~SSTATUS_SPP; //这里允许了中断!!! x |= SSTATUS_SPIE; w_sstatus(x); - 两个进程同时调用sys_print打印数字
父进程循环打印1,子进程循环打印2。如果两条指令之间不加延时,其中一个进程会一直打印,没有机会切换到schedule(),切换到另一个进程,但是在两条打印指令之间加入一段延时,又可以正常运行。为什么?
操作系统中有两个trap入口地址kerneltrap和usertrap,我只在usertrap中判断定时器中断并进行任务切换但是在kerneltrap中只是置位软中断,不进行任务切换。当一个进程循环调用sys_print进行字符打印时,他会不断trap到kernel即S模式,S模式使用kerneltrap,这样以来除非刚刚好在用户模式时触发定时器中断,不然即使定时器时间到达都不会进行任务切换。
解决:在kerneltrap中也加入任务切换。在kerneltrap中加入切换之后,发现最开始系统初始化的顺序也需要更改,pagetable的建立和映射必须要在trap_vector_install() 之前,不然在最开始就会pagefault,两个进程指针一个指向内核线程(kernel_ptr)一个指向当前运行进程(proc_ptr)。需要特别注意的是:在第一个用户进程起来之前也极有可能发生定时器中断,一定要初始化proc_ptr=kernel_ptr;,否则出现pagefault。至此,可以不加延时两个线程循环打印字符。
4.3 创建新进程 fork()
fork() 系统调用是接下来完成的函数,fork() 会将当前进程的全部内容复制一份,包括trapframe和代码
具体会做一些什么事情呢?
- 查看进程数组,可分配的进程是有限的,是否还有可以分配的空位
- 分配pid 设置状态为USED
- 分配pagetable trapframe的空间并映射
- 设置上下文如堆栈的位置
- 根据程序的长度来分配新的物理空间并用walk映射这些物理地址
- 设置状态为RUNNABLE 并返回PID
在看xv6源码时发现:
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
在fork()函数当中并没有为child process复制parent process的trapfram仅仅把child process的trapframe指针指向了parent的trapframe。这样不就会把parent的trapframe内容给修改了吗?
更改initcode代码如下:
.globl start
start:
li a7, 0x20 #系统调用号0x20 uart打印
li a0, 0x30 #0x30 ‘0’
ecall
li a7, 0x20
li a0, 0x31 #0x30 ‘1’
ecall
li a7, 0x01 #系统调用号0x01 fork()
ecall
li a7, 0x20
li a0, 0x32 #0x30 ‘2’
ecall
li a7, 0x20
li a0, 0x33 #0x30 ‘3’
ecall
loop:
j loop
如果代码运行正确:先通过系统调用打印出01,接着程序使用fork() 产生子进程,随后两个进程都会从14行开始执行,打印出2323或者2233。
int fork()
{
struct proc *new_proc_ptr;
pte_t *pte;
unsigned long *proc_mem;
unsigned long pa;
for(int n=0; n<MAX_PROC; n++)
{
if(proc_list[n].state == UNUSED)
{
new_proc_ptr = &proc_list[n];
goto found;
}
}
return -1;
found:
new_proc_ptr->pid = ++pid;
new_proc_ptr->state = USED;
//分配pgt和trapframe的空间 并映射
new_proc_ptr->proc_pagetable = proc_pagetable();
new_proc_ptr->trapframe = kalloc();
map_page(new_proc_ptr->proc_pagetable, (unsigned long)_trampoline, (unsigned long)TRAMPOLINE, 1, PTE_R | PTE_W | PTE_X);
map_page(new_proc_ptr->proc_pagetable, new_proc_ptr->trapframe, 0x3fffffe000, 1, PTE_R|PTE_W);
//设置返回的地址 第一次
new_proc_ptr->context.ra = fork_ret;
new_proc_ptr->context.sp = new_proc_ptr->kstack;
//复制trapframe
*(new_proc_ptr->trapframe) = *(proc_ptr->trapframe);
//设置子进程返回0
new_proc_ptr->trapframe->a0 = 0;
new_proc_ptr->prog_size = proc_ptr->prog_size;
//根据程序的长度复制并映射
for(int n=0; n<proc_ptr->prog_size; n+=4096)
{
pte = walk(proc_ptr->proc_pagetable, n, 0);
if(*pte == 0)
{
panic("pte == 0\n");
}
pa = (unsigned long)(*pte)>>10<<12;
proc_mem = kalloc();
memmove(proc_mem, pa, 4096);
map_page(new_proc_ptr->proc_pagetable, proc_mem, n, 1, PTE_R|PTE_W|PTE_U|PTE_X);
}
//设置程序RUNNABLE
new_proc_ptr->state = RUNNABLE;
return pid;
}
这里部分内容有几个坑: 1. undefined declaration of memcpy
*(new_proc_ptr->trapframe) = *(proc_ptr->trapframe);
涉及到通过指针来复制结构体,尽管没有在代码中使用memcpy但是编译器会优化代码使用memcpy来完成复制,如果没有memcpy的声明就会出现undefined错误。
2. 一直fork()直到用光proc_list[MAX_PROC]数组
 进入usertrap中断处理函数之后一定要先保存sepc寄存器的值,不然可能会被修改导致返回的地址不正确,出现多次fork()。
进入usertrap中断处理函数之后一定要先保存sepc寄存器的值,不然可能会被修改导致返回的地址不正确,出现多次fork()。
//U模式trap处理函数
void user_trap()
{
int syscall_num = proc_ptr->trapframe->a7;
unsigned long trap_cause = r_scause();
if(trap_cause == 8)
{
proc_ptr->trapframe->epc = r_sepc() + 4;
//proc_list[0].trapframe->a0 = 8;
proc_ptr->trapframe->a0 = syscall[syscall_num]();
// proc_ptr->trapframe->epc = r_sepc() + 4;
}
//S模式软件中断
else if(trap_cause == 0x8000000000000001)
{
proc_ptr->trapframe->epc = r_sepc();
//printf("soft interrupt from s mode %p \n", trap_cause);
w_sip(r_sip() & ~2);
back_to_kernel();
// proc_ptr->trapframe->epc = r_sepc();
}
else
{
printf("user_trap(): unexpected scause %p \n", trap_cause);
printf(fault_info[r_scause()].fault_name);
panic("panic/n");
}
user_trap_ret();
}
3. pid不对 pid是一个全局变量初始化成0,但是后来发现变成了一个地址。查看map文件,问题最后定位到pid所在的位置和空闲内存的位置重叠,而空闲内存的管理使用的是最简单的链表,pid的位置正好是空闲内存存指针的地方。原本以为所有初始化之后的全局变量都在data段中存储,查看map文件后发现还有sbss段,里面存放的第一个变量就是pid。修改ld文件考虑sbss段。
什么时候在sbss段什么时候在data段,可能是要看编译器?
4. c编写的用户程序使用fork()函数 判断父子进程时,直接使用fork()的返回值不会出问题,而赋值给局部变量之后再判断pid,子进程出现page fault。debug后发现只分配并映射了stack空间,但是并没有将父进程的stack内容复制给子进程。
4.4 进程睡眠 sleep()
进程会sleep,将当前进程状态设置为SLEEPING然后调用sched(),让当前进程主动放弃cpu
The basic idea is to have sleep mark the current process as SLEEPING and then call sched to release the CPU;
其实就是设置当前的进程是SLEEPING状态,SLEEPING状态的程序自然不能运行,所以我们切换到scheduler进程去重新选择一个进程执行。sched函数其实就是之前使用的backtokernel函数。
void sleep()
{
proc_ptr->state = SLEEPING;
sched();
}
4.1 进程的并发和同步
以多线程计数器为例:
unsigned int share_var;
void *routine(void *arg)
{
for(int i=0; i<1000; i++)
{
share_var++;
}
return NULL;
}
int main()
{
pthread_t thread[2];
pthread_create(&thread[0], NULL, routine, 0);
pthread_create(&thread[1], NULL, routine, 0);
pthread_join(&thread[0], NULL);
pthread_join(&thread[1], NULL);
printf("%d", share_var);
return 0;
}
打印的结果大概率小于2000,在线程1没有将share_var+1的值写回到share_var时,可能线程2就被调度执行,此时线程2读取到的share_var仍然是0,加1后回写,share_var变成1,这时又轮到线程1执行,回写线程1的结果,最后share_var加了两次但是实际结果只加了一次,出现了数据更新的丢失。
需要注意的是即使将这条share_ptr++换成一条汇编的指令执行,仍然不能保证这个自加操作的原子性。即使这个程序在单个单核单线程CPU运行也不能保证原子性,因为CPU现在都是流水线执行,取指 译码 执行 访存 回写这五个阶段都可能会被打断,除非是单个单线程CPU在一个时钟周期可以完成五个阶段才能保证自加操作的原子性。
4.2 spin lock (自旋锁)
We cannot guarantee a thread execution order.
就算有的线程新创建有的线程后创建,后创建的线程仍然有可能比先创建的线程先执行
竞争的产生 有一个共享变量,进程A去操作他的动作还没完成,进程B也去操作这个变量
1. 关闭中断? 进程的切换是通过定时器中断来完成的,在操作共享变量的时候关闭所有的中断可以避免进程的切换,这样就不会产生竞争 但是user space的程序可以有关闭中断的权利危险
2. 使用一个lock变量? 试想设置一个lock变量 如果lock=0 表示没进程在访问 反之则有其他进程正在访问 进程A在访问共享变量之前 先测试lock的值 这样一来好像可以避免竞争 但是lock变量自己也是共享的 如果A进程得到lock=0 在把lock赋值1之前 CPU切换到进程B 进程B也访问了lock 由于A还来得及上锁 B也认为可以操作共享内存 竞争再次发生
3. spin lock
atomic operation (原子操作) 不可被打断的一串命令
TSL Test & Set Lock
#将LOCK的值存入RX 并且设置LOCK=1
TSL RX,LOCK
杂
trampoline.S又映射到了进程空间,又映射了内核空间,通过他的userret我们从kernel的S模式返回到了进程的U模式,当我们在进程的U模式时,有异常(系统调用)或者中断,我们通过uservec进入到内核S模式
5. 文件系统(FS)
5.1 virtio disk
运行在QEMU虚拟机上的xv6,其文件系统的读写是建立在virtio disk上面的,先完成virtio disk的驱动才能进行后面的操作。
5.1.1 修改Makefile
#关闭legacy模式 legacy是之前的旧设备协议
QEMU_OPTS = -global virtio-mmio.force-legacy=false
#磁盘镜像还没好先不指定
QEMU_OPTS += -drive file=/dev/null,if=none,format=raw,id=x0
QEMU_OPTS += -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
#加入刚才得设置
run:
qemu-system-riscv64 $(QEMU_FLAGS) $(QEMU_BIOS) $(QEMU_OPTS) -kernel benos.elf
debug:
qemu-system-riscv64 $(QEMU_FLAGS) $(QEMU_BIOS) $(QEMU_OPTS) -kernel benos.elf -S -s
5.1.2 生成测试img文件
上面的配置只能测试磁盘得初始化不能测试读写,因为没有磁盘镜像。用dd工具生成一个随机得磁盘镜像来测试读写
#block size = 1024k
dd if=/dev/urandom of=mydisk.img bs=1M count=10
5.1.3 virtio驱动
1. 使能PLIC管理的磁盘中断
virtio disk的中断是由PLIC来控制的,PLIC由将这个中断传递给CPU,PLIC的中断信号对于CPU来说是外部中断,因此要使能S模式的外部中断。
w_sie(r_sie() | (0x01<<9));
2. 具体读写操作
virtio disk读写都要通过struct buf结构体来完成,buf结构体的dev成员设置0x01
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
//struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[1024];
};
测试virtio_disk_rw,向第0个block写1024个byte,内容都是0
struct buf *test_buf = (struct buf *)kalloc();
memset(test_buf, 0, 4096);
test_buf->dev = 0x1;
test_buf->blockno = 0;
test_buf->valid = 0;
test_buf->refcnt = 1;
virtio_disk_rw(test_buf, 1);
在内核当中直接测试的时候一定要主要这个test_buf分配空间别放在free_mem之前了,不然后面的设置就全都没用了。
用hexdump查看写测试之前的磁盘内容,一行是16bytes,从0x0000开始:

运行程序写一个block之后,第一个block已经成功变成0

读写失败的情况:在gdb中可以查看test_buf具体的值,dev成员的值不对,block的值也不对,可能是由于test_buf有些成员没有设置正确,返回的data数组的值也是任意的。
(gdb) p /x *test_buf
$1 = {valid = 0x0, disk = 0x0, dev = 0x1000, blockno = 0x3, refcnt = 0x1, pre = 0x0, nxt = 0x0, data = {0x0 <repeats 129 times>, 0xf0,
0xff, 0xff, 0x2, 0x0 <repeats 156 times>, 0xd0, 0xff, 0xff, 0x2, 0x0 <repeats 156 times>, 0xb0, 0xff, 0xff, 0x2,
0x0 <repeats 156 times>, 0x90, 0xff, 0xff, 0x2, 0x0 <repeats 156 times>, 0x70, 0xff, 0xff, 0x2, 0x0 <repeats 156 times>, 0x50, 0xff,
0xff, 0x2, 0x0 <repeats 91 times>}}
FAT(File Allocation Table)
用链表把一个一个block链接起来,链表是集中存放并且有多个备份
5.2 基于Inode的文件系统
inode会在磁盘和RAM当中各一份,RAM当中我们直接写作inode,磁盘当中我们写作dinode作为区分。
#define NDIRECT 12
#define NINDIRECT 1
//总大小64bytes
struct dinode
{
//用major来指定是哪种设备 minor来指定是这种设备的哪一个
short major;
short minor;
//三种type:file device directory
short type;
short nlink;
unsigned int size;
//12个直接块 1个间接块
unsigned int block_addr[NDIRECT+NINDIRECT];
};
xv6当中定义NINDIRECT
#define NINDIRECT BSIZE/(sizeof(unsigned int))
虽然dinode只用了一个指针来指向indirect block,但是一个间接块当中其实含有Block_Size/sizeof(指针长度) 个指向block的指针。

inode是从dinode读取填入的。
struct inode
{
unsigned int dev_num;
unsigned int inode_num;
int valid;
int ref;
struct dinode inode_copy;
};
Directory Entry 目录项 如果没有目录,那么所有的文件都是平行的。目录是一种特殊的文件,一级目录就可以理解成一个文件夹。我们每创建一个文件就会分配一个inode,每创建一个文件夹也会分配inode,文件的数据块存放的是文件的内容,目录的数据块存放的是当前文件夹下面文件和子文件夹的dirtectory entry用struct dirent表示。所以每新添加一个文件需要朝他所在的文件夹的数据块添加他的dirent
//大小16bytes
struct dirent {
ushort inum;
char name[DIRSIZ];
};
5.2.1 创建文件系统到磁盘主要API
//小端转换
unsigned short xshort(unsigned short val);
unsigned short xint(unsigned int val);
//根据block号 读写缓冲buf内容来写
wr_block(unsigned int n_block, void *buf);
rd_block(unsigned int n_block, void *buf);
//读写磁盘里面的inode
wr_inode(unsigned int inum, struct dinode *new_dinode);
rd_inode(unsigned int inum, struct dinode *new_dinode);
//分配新的inode 并写入inode blk
//注意!!! inode结构体在使用之前一定要先将里面的东西全部清零
inode_alloc(unsigned short file_type);
//inode增加内容
inode_append(unsigned int inum, void *buf, int n);
大小端转换如果本来就是小端了那么使用xint函数输入等于输出。xv6使用了这个转换应该主要是考虑到会用在大端的磁盘上面。
实现一个最基本的文件系统结构,先不要log块
| 分区 | boot | superblock | inode block | bitmap block | data blocks |
|---|---|---|---|---|---|
| 块号 | 0 | 1 | 2 | 3 | 4及之后 |
| 起始地址 | 0x00 | 0x400 | 0x800 | 0xc00 | 0x1000 |
里面比较费劲的实现应该就是inode_append
//往对应inode文件添加内容
//*xinput对应待添加数据的首地址
//n对应数据长度
void inode_append(unsigned int inum, void *input, int len)
{
char *p = (char *)input;
struct dinode dinode_buf;
unsigned int offset, fbn, actual_wr_len;
char indirect[BSIZE / sizeof(unsigned int)];
unsigned int blk_num;
char data_buf[BSIZE];
//读取inode到buf里面
rd_inode(inum, &dinode_buf);
offset = xint(dinode_buf.size);
printf("offset = 0x%x\n", offset);
//循环条件 如果添加的内容还没有添加完
while(len > 0)
{
printf("length = 0x%x\n", len);
//完整块的数量
fbn = offset / BSIZE;
printf("fbn = %u\n", len);
//如果这个文件数据块的数量小于直接块的数量
if(fbn < NDIRECT)
{
//对应还没有分配的情况 或者刚刚好文件大小是BSIZE的整数倍
if(xint(dinode_buf.data_address[fbn] == 0))
{
dinode_buf.data_address[fbn] = xint(freeblock++);
}
blk_num = xint(dinode_buf.data_address[fbn]);
}
//如果超过了直接快
else
{
//看看间接块的地址有没有分配
if(xint(dinode_buf.data_address[NDIRECT]) == 0)
{
dinode_buf.data_address[NDIRECT] = freeblock++;
}
//读取间接块
rd_sec(dinode_buf.data_address[NDIRECT], (char *)indirect);
//查看有没有分配
if(indirect[fbn-NDIRECT] == 0)
{
indirect[fbn-NDIRECT] = freeblock++;
//分配之后将数据写回去
wr_sec(dinode_buf.data_address[NDIRECT], (char *)indirect);
}
blk_num = indirect[fbn-NDIRECT];
}
//读取这一块的内容到缓存
rd_sec(blk_num, data_buf);
//等待添加的内容可能比当前块剩余的空间少或者多
//我们只写入最少的
//如果直接按照剩余空间长度来写 可能会造成segment fault
actual_wr_len = min(n, (fbn+1)*BSIZE-offset);
printf("actual_wr_len = %d\n", actual_wr_len);
memcpy(data_buf+offset-(fbn*BSIZE), p, actual_wr_len);
//回写
wr_sec(blk_num, data_buf);
len -= actual_wr_len;
offset += actual_wr_len;
p += actual_wr_len;
}
dinode_buf.size = offset;
wr_inode(inum, &dinode_buf);
}
如图所示 第0块 [0x3ff:0x00] 是boot 没有内容 第1块 [0x7ff:0x400] 是sb 起始内容是设置的magic number 第2块 [0xaff:0x800] 是inode块 每条inode长64byte对应四行的长度 从第12byte开始就是对应的direct block的块号 第3块 [0xfff:0xc00] 是bitmap 没有填写 第4块 [0x13ff:0x1000] 是数据块 创建rootdir时将这块分配给他作为datablock 用于存放rootdir文件夹下的子文件和子文件夹
rootdir是第一个创建的文件类型是文件夹 分配的数据块号是4对应 [0x13ff:0x1000] 后来又添加了两个文件 这两个文件属于rootdir 因此会创建相应的directory entry到4号数据块


问题
在使用read_sb读取superblock的内容时,最开始偷懒直接用函数当中的临时变量struct buf结构体来存储virtio返回的数据块,在初始化的时候没问题,但是放在fork_ret当中去执行总是读取的不对,data里面全部是空。换成heap上分配的内存来存储就没问题,栈空间不够?但是gdb查看时发现是够用的,暂时还不知道为什么。
5.3 exec()系统调用
exec()和文件系统的实现密切相关,本来在fork()系统调用之后接着就实现exec()系统调用,但是在查看了xv6的源码之后发现没有文件系统还真写不出来。exec()的任务很简单:
exec is a system call that replaces a process’s user address space with data read from a file, called a binary or executable file.
exec()执行新的程序,他的方式就是把当前进程的一切替换成将要执行的程序的内容。
| elf文件组成 |
|---|
| elf header |
| program header |
| … |
| .init |
| .plt |
| .text |
| .rodata |
| .data |
| .bss |
| .comment |
| .symtab |
| … |
| section header |
- 通过path字符串找到这个文件的inode,inode包含了这个文件的所有信息
char *get_nxt_name(char *path, char *name);
int get_inode(char *path, struct inode *ino);
- 根据inode提供的信息解析elf header的内容
struct elfhdr {
uint magic; //必须是0x7f+ELF
uchar elf[12]; //
ushort type; //文件类型
//可重定位文件(Relocatable File)
//可执行文件(Executable File)
//共享目标文件(Shared Object File)等几种类型
ushort machine; //架构 riscv对应243
uint version;
uint64 entry; //程序入口
uint64 phoff; //Program Header Table 在文件中的偏移量
uint64 shoff; //Section Header Table 在文件中的偏移量
uint flags; //标志位,表示与文件相关的处理器标志
ushort ehsize; //ELF Header大小 通常是 52 字节。
ushort phentsize; //Program Header Table 中每个表项的大小。
ushort phnum; //Program Header Table 中表项的数量
ushort shentsize; //Section Header Table 中每个表项的大小。
ushort shnum; //Section Header Table 中表项的数量
ushort shstrndx; //包含节名称的字符串表在 Section Header Table 中的索引
};
//program header
struct proghdr
{
unsigned int type;
unsigned int flags;
unsigned long off;
unsigned long vaddr;
unsigned long paddr;
unsigned long filesz;
unsigned long memsz;
unsigned long align;
};
使用readelf工具可以帮助我们分析写入的elf文件
注意:program header可能会有多个!我们需要根据elf header的信息来写: 最开始只使用汇编来编写用户代码的时候没有这些问题,但是在使用c之后,使用int main()的方式来编写用户程序,在生成elf文件时,会按照user.ld指定的方式来链接代码段和数据段


//从磁盘加载程序到内存的api
- 根据elf header分配pgt 填充程序各段的位置
在完成elf文件程序装载时又发现:因为之前都是很短的程序所以我们分配的都是一个页就行了
int exec(char *path, char **argv)
{
...
//分配新的页表
pgt_t user_pagetable = proc_pagetable();
//映射trampoline
//映射trapframe
//映射stack
map_page(user_pagetable, (unsigned long)_trampoline, (unsigned long)TRAMPOLINE, 1, PTE_R | PTE_X);
map_page(user_pagetable, (unsigned long)proc_ptr->trapframe, (unsigned long)TRAMPOLINE-0x1000, 1, PTE_R | PTE_W);
map_page(user_pagetable, (unsigned long)stack, (unsigned long)4096, 1, PTE_R | PTE_W);
//读取elfhdr proghdr
//分配装载程序内容的物理地址并映射
//装载程序内容到刚才分配的物理地址
read_elfhr(&proc_elfhdr, &proc_proghdr, &proc_inode);
uvmalloc(user_pagetable, 0, proc_proghdr.memsz, 0);
loadsec(user_pagetable, &proc_inode, proc_proghdr.vaddr, proc_proghdr.off, proc_proghdr.filesz);
//填写程序结构体
proc_ptr->proc_pagetable = user_pagetable;
proc_ptr->prog_size = 4096;
proc_ptr->trapframe->epc = proc_elfhdr.entry;
proc_ptr->trapframe->sp = 4096+4096;
return 0;
}
测试exec()系统调用
在第一个用户程序initcode当中调用exec
5.4 File Descriptor Layer
在完成inode层之后本想紧接着实现一系列和文件相关的系统调用如pipe(),却发现在inode之上都还有一层。先来看看在完成inode之后我们得到了什么?我们可以以文件路径的方式访问存储在img文件中的任何一个文件或者文件夹,但是这离把所有的资源都抽象成文件还不够。
我们还需要一层File Descriptor Layer:

xv6用struct file结构体实现了所有资源都是文件的统一,struct file就是对inode和pipe的一个新的封装
struct file {
enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE } type;
int ref; // reference count
char readable;
char writable;
struct pipe *pipe; // FD_PIPE
struct inode *ip; // FD_INODE and FD_DEVICE
uint off; // FD_INODE I/O offset
short major; // FD_DEVICE
};
使用路径名并通过file descriptor的方式打开读写磁盘上的文件示意图如下:
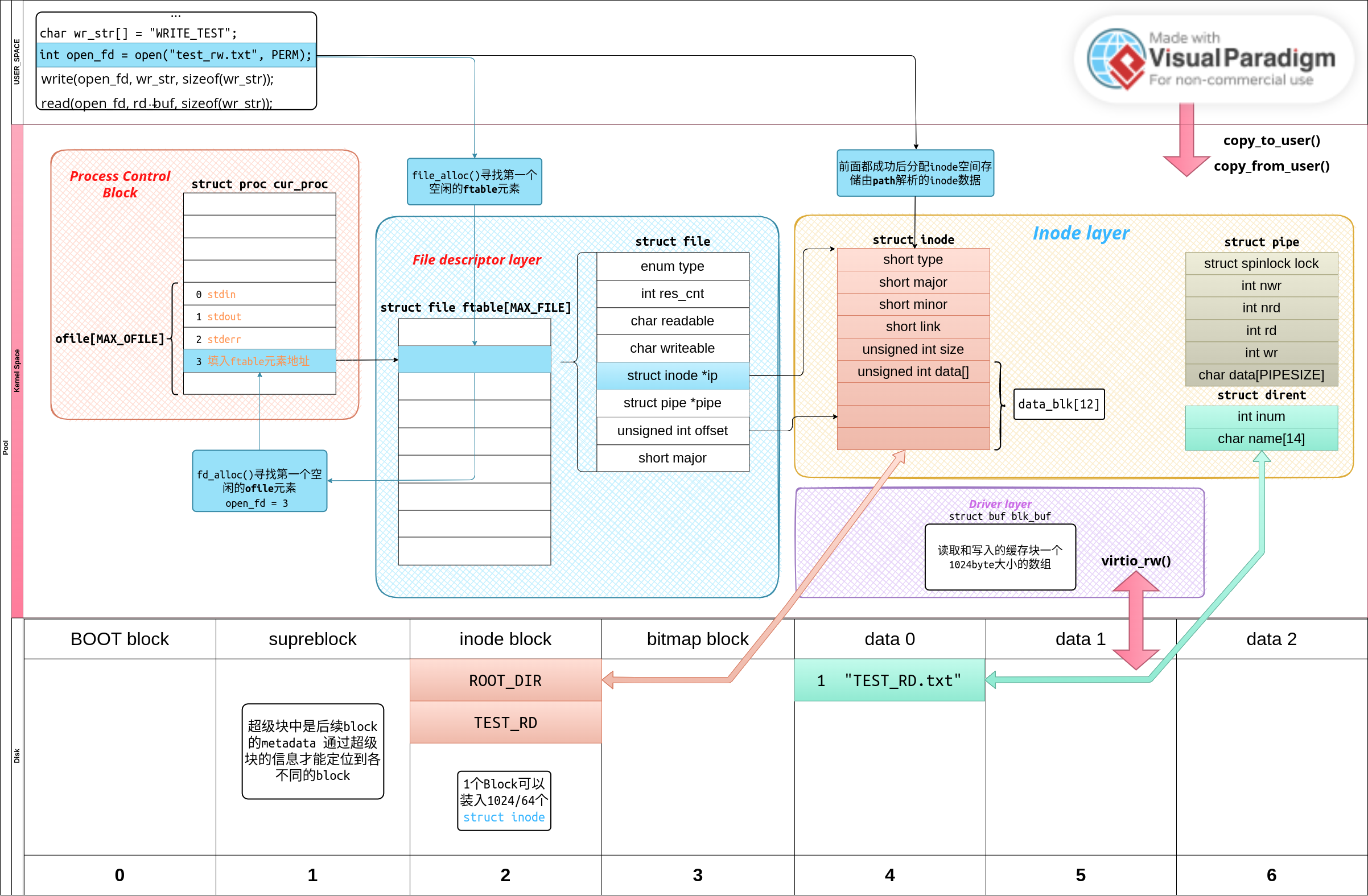
在图中可以清晰的知道通过open函数返回的fd就是进程控制块(PCB)中ofile数组中的元素号码,内核中通过ofile[fd]寻址到其对应的struct file,struct file中对应的不同的文件类型分别有不同的指针指向对应的结构体,例如如果这个struct file的类型是FD_FILE那么就设置
5.4.1 copy_from_user() copy_to_user()
5.4.2 pipe()
//用户程序使用pipe的声明
int pipe(int pipefd[2]);
pipe从他的结构体定义中可知就是一块RAM中的内存,有一些读写参数加一把锁(写完之前不能读,读完之前不能写)。新建一个pipe和新建一个文件不同的是pipe有读写两个端口,这两个端口要分别对应不同的fd,fd[2]就对应两个struct file,而一般的文件只需要一个是struct file



6. 开启多核
走到这里发现很多的系统调用和函数都涉及到锁,还是开启多核把最基本的并发同步实验做了吧。
QEMU开启多核添加
为printf()加锁
//xv6使用的是gcc编译器生成的命令
void acquire(struct spinlock *lk)
{
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
{
;
}
__sync_synchronize();
}
反汇编之后可以看到:
0000000080201fa4 <acquire>:
80201fa4: fe010113 addi sp,sp,-32 80201fa8: 00813c23 sd s0,24(sp)
80201fac: 02010413 addi s0,sp,32
80201fb0: fea43423 sd a0,-24(s0)
80201fb4: 00000013 nop
80201fb8: fe843783 ld a5,-24(s0)
80201fbc: 00100713 li a4,1
80201fc0: 0ce7a72f amoswap.w.aq a4,a4,(a5)
80201fc4: 0007079b sext.w a5,a4
80201fc8: fe0798e3 bnez a5,80201fb8 <acquire+0x14>
80201fcc: 0ff0000f fence
80201fd0: 00000013 nop
80201fd4: 01813403 ld s0,24(sp)
80201fd8: 02010113 addi sp,sp,32
80201fdc: 00008067 ret
栈帧基本上是16byte的倍数 前2个byte是ra和s0(fp),后面放参数
- [] semaphore信号量
- sleep wakeup实现等待队列
sleep() wakeup()同步机制
void sleep(unsigned long *chan)
{
proc_ptr->state = SLEEPING;
proc_ptr->sleep_chan = (unsigned long)chan;
sched();
}
void wakeup(unsigned long *chan)
{
for(int n=0; n<MAX_PROC; n++)
{
if((proc_list[n].state == SLEEPING) && (proc_list[n].sleep_chan == (unsigned long)chan))
{
proc_list[n].state = RUNNABLE;
}
}
}
int sys_sleep()
{
int interval = proc_ptr->trapframe->a0;
unsigned long tick_st = systicks;
while(systicks-tick_st < interval)
{
sleep(&systicks);
}
}
注意:sleep()时需要将原本持有的锁释放 否则造成死锁
- todo
- 对比linux
uboot启动传参数
/*
*r2 DTB表的位置
*/
kernel_entry(0, machid, r2);
uboot为什么从0x20000开始:DOS时代使用1M一下的内存
uboot跳到head.S
7. 内存管理
1. 操作系统为什么需要能够连续的物理页?
有了虚拟空间之后似乎好像不再依赖连续的地址空间了,但是从linux使用的buddy allocator来看,操作系统仍然需要经常分配连续的物理地址。
- 某些硬件设备(如DMA控制器)可能要求连续的物理页来进行数据传输。磁盘大文件传输。
- 尽管虚拟内存可以将物理内存映射到不连续的虚拟地址空间,但在某些情况下,连续的物理页可以带来性能上的优势。例如,连续的物理页可以提高缓存的命中率,减少内存访问的延迟。
之前实现的物理内存分配中只有一个单位–页,但是很明显我们还需要一种小内存的分配管理办法,不然这个内存分配的内部碎片就太大了,哪怕我们只需要malloc(1)也会分配4K的空间。
- 完善内存管理