Rk3588_baremetal
rk系列裸机
1. 准备
现在厂商都一套自己的打包软件,按照如hceng讲解的rk3399来做理论上应该可以,但是我在实验时发现不行,下载之后没有相应的串口显示。
查看这个radax build uboot指南之后,我们可以知道:

经过尝试之后,发现只需要idbloader就可以启动,我们继续看这个idbloader是怎么生成的:
./tools/mkimage -n rk3588 -T rksd -d ../rkbin/bin/rk35/rk3588_ddr_lp4_2112MHz_lp5_2736MHz_v1.08.bin:spl/u-boot-spl.bin idbloader.img
在官方提供的sdk中的mk-uboot.sh找到上述命令,上面的命令合成了ddr和spl两个文件,spl是用于载入uboot的,我们不需要,所以我们只需要将我们自己的bin文件替换spl文件就可以启动了。
根据文件我们可以看到其实3399的bootcode可以用mkimage来制作:
tools/mkimage -n rk3399 -T rksd -d ../rkbin/bin/rk33/rk3399_ddr_800MHz_v1.25.bin idbloader.img
使用uboot启动程序
直接使用裸机程序出现一个问题:从el3到el2不能成功,即使代码在qemu上面没有问题,只能直接从el3到el1。我感觉可能是没有使用atf的原因,所以想使用uboot来引导,编译的uboot已经包括atf了。
rk3588的uboot并没有支持网络驱动,所以没法nfs或者tftp加载应用程序,需要将编译的应用程序放在sd卡中,利用其他命令加载:
//保证自己的sd卡是fat格式
//fatload <interface> <device> <load_addr> <filename>
//mmc 表示sd卡或者是emmc 我的机器上1是sd卡 0x8300000是加载到内核的地址
fatload mmc 1 0x8300000 rk3588.bin
//跳转到0x8300000运行
go 0x8300000
使用uboot引导之后可以正常下降到el1,但是出现了下降到el1之后,data段被清零了,最开始是在el1使用printf()不能打印全局变量会进入trap,但是在el2使用printf()一切正常,最后定位到data段在进入el1之后清零了。目前不清楚是什么原因导致的,可能el2到el1还有一些特殊操作。我最后用了一个trick:在el2的时候将程序重定位到新的位置,数据段的问题解决了但是暂时不清楚还有没有什么其他的bug。
X开头的是64bits的寄存器 W开头的是32bits寄存器一定要区分开 rk3588上的外设基本上都是32bit的 不能用X寄存器去写
qemu virt开发板帮助验证程序
static const MemMapEntry base_memmap[] = {
/* Space up to 0x8000000 is reserved for a boot ROM */
[VIRT_FLASH] = { 0, 0x08000000 },
[VIRT_CPUPERIPHS] = { 0x08000000, 0x00020000 },
/* GIC distributor and CPU interfaces sit inside the CPU peripheral space */
[VIRT_GIC_DIST] = { 0x08000000, 0x00010000 },
[VIRT_GIC_CPU] = { 0x08010000, 0x00010000 },
[VIRT_GIC_V2M] = { 0x08020000, 0x00001000 },
[VIRT_GIC_HYP] = { 0x08030000, 0x00010000 },
[VIRT_GIC_VCPU] = { 0x08040000, 0x00010000 },
/* The space in between here is reserved for GICv3 CPU/vCPU/HYP */
[VIRT_GIC_ITS] = { 0x08080000, 0x00020000 },
/* This redistributor space allows up to 2*64kB*123 CPUs */
[VIRT_GIC_REDIST] = { 0x080A0000, 0x00F60000 },
[VIRT_UART] = { 0x09000000, 0x00001000 },
[VIRT_RTC] = { 0x09010000, 0x00001000 },
[VIRT_FW_CFG] = { 0x09020000, 0x00000018 },
[VIRT_GPIO] = { 0x09030000, 0x00001000 },
[VIRT_SECURE_UART] = { 0x09040000, 0x00001000 },
[VIRT_SMMU] = { 0x09050000, 0x00020000 },
[VIRT_PCDIMM_ACPI] = { 0x09070000, MEMORY_HOTPLUG_IO_LEN },
[VIRT_ACPI_GED] = { 0x09080000, ACPI_GED_EVT_SEL_LEN },
[VIRT_NVDIMM_ACPI] = { 0x09090000, NVDIMM_ACPI_IO_LEN},
[VIRT_PVTIME] = { 0x090a0000, 0x00010000 },
[VIRT_SECURE_GPIO] = { 0x090b0000, 0x00001000 },
[VIRT_MMIO] = { 0x0a000000, 0x00000200 },
/* ...repeating for a total of NUM_VIRTIO_TRANSPORTS, each of that size */
[VIRT_PLATFORM_BUS] = { 0x0c000000, 0x02000000 },
[VIRT_SECURE_MEM] = { 0x0e000000, 0x01000000 },
[VIRT_PCIE_MMIO] = { 0x10000000, 0x2eff0000 },
[VIRT_PCIE_PIO] = { 0x3eff0000, 0x00010000 },
[VIRT_PCIE_ECAM] = { 0x3f000000, 0x01000000 },
/* Actual RAM size depends on initial RAM and device memory settings */
[VIRT_MEM] = { GiB, LEGACY_RAMLIMIT_BYTES },
};
ROCKPI5B IO口

奇怪的错误
- freestanding的printf不知道什么时候开始,使用就报错,最后发现是在可变参函数的入栈出了错误esr=0x1fe00000,未知错误,检查了sp的对齐没有问题不知道怎么回事,也不是没有isb的问题。最后在osdev上发现了和我一样的问题
CFLAGS += -mgeneral-regs-only
- bootcode指南的代码尝试不对
注意
异常处理函数的参数不对会导致错误
2. ARMv8
SPECIAL 寄存器


SPSR_ELx (Saved Process Status Register)
SPSR_ELx寄存器在异常发生时会复制PSTATE值,以便在退出异常时恢复。PSTATE包括计算标志位(例如溢出,进位等),中断屏蔽位(DAIF),执行状态(aarch64 aarch32),异常出现时运行在异常等级(EL0 EL1 EL2 EL3),使用哪一个SP寄存器(sp_el0 sp_elx)。
ELR_ELx (Exception Link Register)
异常处理完毕的返回地址。
SP_ELx (Stack pointer)
每个异常等级都有对应的SP寄存器,高级别的寄存器都可以使用SP_EL0,需要用户在程序中选择,默认使用SP_ELx。
armv8汇编
1. 栈操作
sp的值不会自己加减,需要手动维护,写c时汇编会汇编出sp操作
// x8入栈
str x8, [sp, #-8]! // *(sp - 8) ← x8
// sp ← sp - 8
str x8, [sp, #-8] //有无感叹号的区别就在于 入栈之后对SP进行操作与否
// x8出栈
ldr x8, [sp], #8 // x8 ← *sp
// sp ← sp + 8
虽然上述通用指令可以完成SP的维护但是这还不够,Armv8的convention要求栈应该以16bytes对其(keep the stack aligned to a multiple of 16)
// x8和x11入栈
stp x8, x11, [sp, #-16]! // *(sp - 16) ← x8
// *(sp - 16 + 8) ← x11
// sp ← sp - 16
// x8和x11出栈
ldp x8, x11, [sp], #16 // x8 ← *sp
// x11 ← *(sp + 8)
// sp ← sp + 16
2. adr adrp ldr
ldr伪指令加载的是绝对地址(链接脚本中的地址)
adr/adrp加载的是当前程序实际运行的物理地址 adr+-4k adrp+-4G
adrp指令获取label所在的page的起始地址
3. 跳转
跳转以前没怎么注意,但是跳转是有范围的,在启用了虚拟地址之后如果还是使用bl b的话,他们都是pc-related所以跳转范围其实只有+-128m,需要使用绝对跳转br
3. 异常处理
| 特权模式 | Column 2 | 系统调用指令 |
|---|---|---|
| EL0 | 应用程序 | SVC |
| EL1 | 操作系统 | HVC |
| EL2 | hypervisor 虚拟化 | SMC |
| EL3 | secure monitor 安全世界 |
读取current_el返回值对应exception level的关系:
最开始一直搞不清armv8的sp sp_el0 sp_elx,sp_sel的bit0决定当前使用的是spel0还是spelx
在物理上sp寄存器有4g

通过ARM提供的异常处理流程图可以看出,在异常发生之后,从异常处理的entry代码开始就已经进入到同等级或者更高等级的exception level中了,所以在异常处理代码中使用的SP就是和之前不同的SP
1. 异常返回
/*执行eret完成异常的返回*/
eret
执行eret时会拷贝SPSR_ELn中的状态到PSTATE中去,之后程序就开始从ELR_ELn中装载的地址运行。
注意:异常的进入保存和退出恢复的顺序很重要 仔细检查 stp ldp指令基址的加减顺序
2. 中断处理
中断属于异步异常(asynchronous exception),在Armv8架构中,进入异常之后会将中断屏蔽DAIF全部置0,如果要使能中断嵌套需要在读取intid之后手动清楚DAIF屏蔽位
进入Handler()之后:
- 读取ICC_IAR1_EL1寄存器 获取对应的中断号
- 写中断号到ICC_EOIR1_EL1 清除相应的中断标志位
- 重新打开DAIF
注意:不需要重新置位DAIF,重新置位会造成中断嵌套,退出中断处理时从spsr中自动读取之前保存的状态
1. PPI(定时器) SPI(UART)
问题:uart中断使能接收中断之后,使用键盘给rk3588发送字符导致程序暂停,最开始以为是进入到其他的中断处去了,最后发现是与UART的状态位冲突,卡死在uart_send_char()的while循环中,在发送标志位检测中添加超时机制,解决。
esr = 0x96000046 stp一般是是使用了空指针 或者是操作了没有mmu映射的内存。
esr = 0x96000047 ldp
2. GIC-500 GIC-600
rk3399使用gic500,rk3588使用gic600。
//rk3588s.dtsi
gic: interrupt-controller@fe600000 {
compatible = "arm,gic-v3";
#interrupt-cells = <3>;
#address-cells = <2>;
#size-cells = <2>;
ranges;
interrupt-controller;
reg = <0x0 0xfe600000 0 0x10000>, /* GICD */
<0x0 0xfe680000 0 0x100000>; /* GICR */
interrupts = <GIC_PPI 9 IRQ_TYPE_LEVEL_HIGH>;
its0: msi-controller@fe640000 {
compatible = "arm,gic-v3-its";
msi-controller;
#msi-cells = <1>;
reg = <0x0 0xfe640000 0x0 0x20000>;
};
its1: msi-controller@fe660000 {
compatible = "arm,gic-v3-its";
msi-controller;
#msi-cells = <1>;
reg = <0x0 0xfe660000 0x0 0x20000>;
};
};
1. 中断类型
- SPI (Shared Peripheral Interrupt)
共享的外设中断,每一个SPI都可以被route到一个核心,比如uart
- PPI (Private Peripheral Interrupt)
每个核心私有的外设中断,比如cortex-a53上的PS定时器等
- SGI (Software Generated Interrupt)
主要用于核间通信
- LPI (Locality-specific Peripheral Interrupt)
用于PCIe?
2. GIC结构

- Distributor
主管SPI和secure
一个SoC只有一个Distributor进行一些全局设置,主要和SPI相关,所有的核心共用的外设如果发出了中断请求,这个中断请求根据具体情况被发送到指定的核心,从这个结构图上来看也只有Distributor可以完成这个任务,因为是全局设置所以还有一些secure相关的设置也在这里。
设置个
- Redistributor
主管PPI和SGI
每个核心都有对应的Redistributor,在这里设置私有中断应该是比较合适的
- CPU Interface
主管priority
上面两块的设置都不涉及到中断优先级
3. 初始化GIC
mpidr_el1对应aff编号(read only)
-
初始化Distributor
-
初始化Redistributor
-
初始化CPU
4. 内核空间用户空间的映射
1. MMU基本
rk3588的trm中提到有两个MMU600实例,但是这并不是用来操作普通内存地址的,其中一个链接到pcie高速外设另一个php链接到sata usb3等。普通的操作地址使用cortex a核心内部的MMU。
- TCR_EL1 页表设置 4k 16k 64k 48位 39位等
- MAIR_EL1 内存权限
- TTBR0_EL1 存放pagetable的地址
- TTBR1_EL1 存放pagetable的地址
有两个页表基址寄存器那么转换的时候用那一个呢?
虚拟地址VA在(0x00, 0x0000FFFFFFFFFFFF)使用TTBR0_EL1
虚拟地址VA在(0xFFFF000000000000, 0xFFFFFFFFFFFFFFFF)使用TTBR1_EL1
需要注意的是:尽管有64位宽的地址和数据总线但是ARMv8要求在48位宽内完成映射

mmu使能之前至少需要完成3步设置:
- 设置tcr_el1
- 设置mair_el1
- 设置ttbr0_el1 ttbr1_el1
问题:使能MMU之后,多次进入串口中断会触发PC没有对齐的异常。后来检查发现内存映射没有做好,之前完整映射时一直有remap没有检查,只是少映射了数据段的长度,串口打印时会使用到没有映射地址的数据,导致异常。解决:检查映射后更改,不再触发。
2. 映射kernel代码到内核空间
uboot引导内核之后,内核一直运行在低地址,这个地方是操作系统预留给用户程序的空间,我们需要尽快将内核映射到内核空间(0xffff000000000000)去。操作MMU完成两个页表的映射,_pagetable0用于完成1:1映射(identical mapping)以保证在开启MMU之后的下一条指令仍然能够正常运行不触发page fault。_pagetable1用于映射内核代码的物理地址到内核空间,映射完成之后使用绝对跳转到高地址执行内核。
adr x0, before_kernel /*完成映射并开启MMU*/
blr x0
ldr x0, =kernel_main /*跳转到kernel_main链接地址去执行*/
br x0
问题:页表切换之后不能访问,但是如果在原来的页表上增加映射又可以继续执行,没有设置data尚不清楚机制,排查发现是忘记更换堆栈指针到高地址。最开始使用的SP空间一直在低地址,切换了低地址页表之后SP的空间不能访问。在完成内核映射到高地址之后就应该重新设置SP到高地址了。
3. 配置页表
和之前RISCV上完成的等比映射(虚拟地址=物理地址)相比,在RK上我使用了直接映射(虚拟地址=物理地址+固定偏移)的方式,这样需要对原有的map_page()函数改进。原因在于进程的页表基址和页表项中存储的地址都是物理地址,但是操作这些页表需要虚拟地址。
5. 系统调用框架
1. SVC
与RISCV不同的是,RISCV中ecall指令传递参数的方式是直接通过x0寄存器,Armv8中使用svc #imm直接将数字硬编码到指令中,参数的传递通过ESR寄存器完成,ESR寄存器在面对不同的异常类型时,字段的解码方式不同。

系统调用的具体参数就遵从armv8的call procedure ABI,x0到x7存放param,x8返回值。
2.函数调用标准(Procedure Call Standard)
| 寄存器 | 描述 |
|---|---|
| x0~x7 | 传递参数和结果,如果参数多于8个,使用stack |
| x8 | 间接结果,例如返回结构体的指针 |
| x30(LR) | 函数返回地址 |
6. User-Kernel Transition & Context Switch
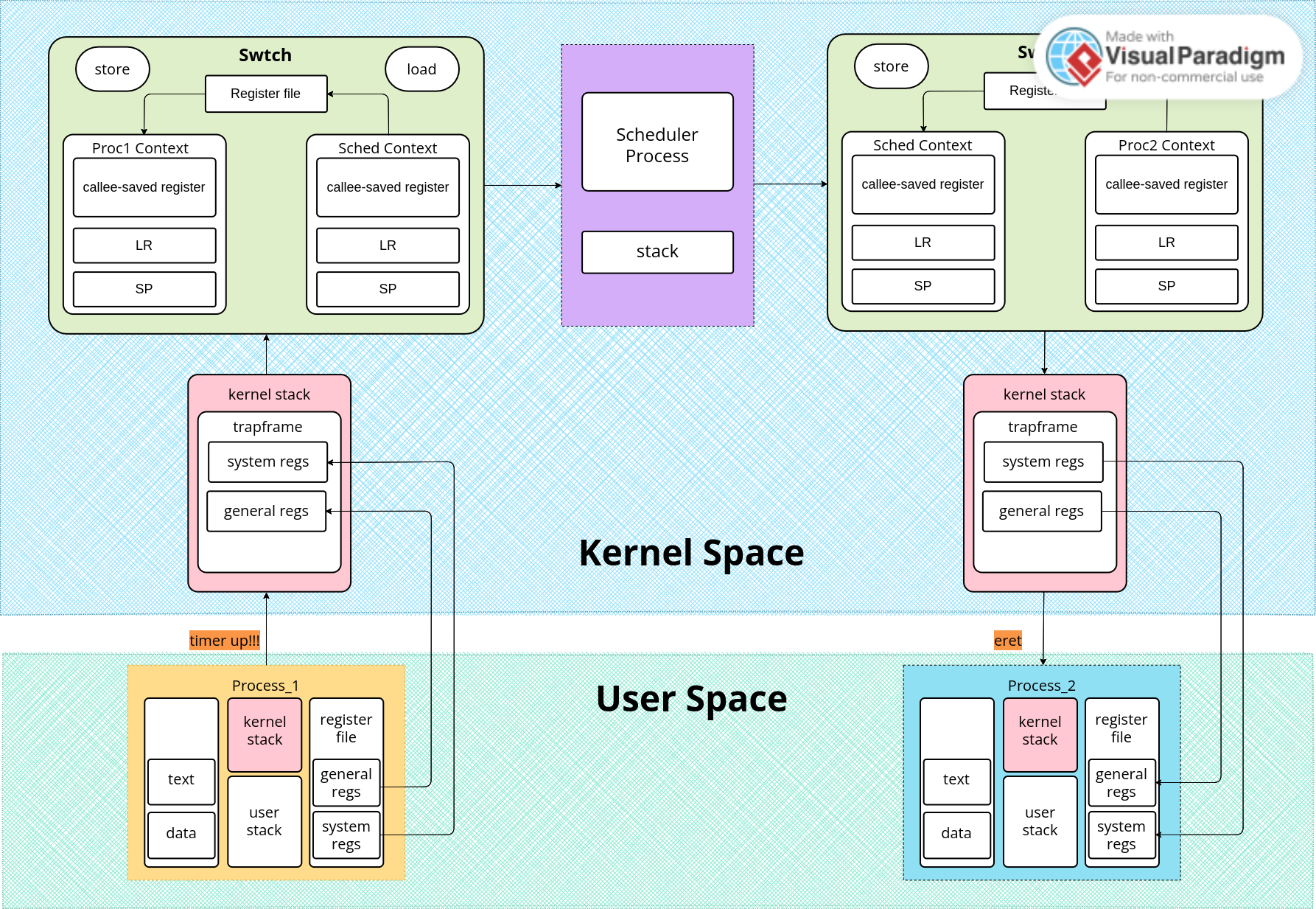
1. struct context
struct context
{
unsigned long reg[11]; /* x19~x28 x29(FP)*/
unsigned long sp;
unsigned long lr;
};
在context结构体的定义中没有PC寄存器的值,如何返回到另一个进程之前运行的地方?swtch函数最后使用ret指令返回到lr中装载的地址,而lr中的地址正好是上一次进入swtch函数时装载的,所以ret之后刚好是swtch执行之后。
2. struct trapframe
trapframe是发生异常时的cpu状态快照,需要保存所有的寄存器。异常发生之后,在异常入口按照trapframe的结构将trapframe压栈或者存储在内存页中(xv6-riscv)。
struct trap_frame
{
unsigned long general_reg[30];
unsigned long lr; //x30
unsigned long sp_el0;
unsigned long spsr_el1;
unsigned long elr_el1;
unsigned long esr_el1;
unsigned long trap_type;
};
3. trapframe和context有什么区别?
处理器上下文和进程上下文
在xv6-riscv中trapframe是以一页的形式映射在用户空间的,每一个用户进程都有一页单独存放trapframe。trapframe顾名思义也就是在异常发生的那一刻对于cpu状态的保存,当异常处理完成之后,我们需要返回到cpu之前的状态继续执行被打断的程序。

参考xv6在用户层异常进入和退出的代码就很容易明白trapframe的含义:
/*uservec是用户空间中发生异常时的异常入口*/
uservec:
csrw sscratch, a0
li a0, 0x3fffffe000
sd ra, 40(a0)
sd sp, 48(a0)
sd gp, 56(a0)
...
sd t3, 256(a0)
sd t4, 264(a0)
sd t5, 272(a0)
sd t6, 280(a0)
userret:
sfence.vma zero, zero /*更换页表*/
csrw satp, a0
sfence.vma zero, zero
li a0, 0x3fffffe000 /*加载trapframe地址到a0*/
ld ra, 40(a0) /*从trapframe中恢复寄存器的值*/
ld sp, 48(a0)
ld gp, 56(a0)
ld tp, 64(a0)
...
ld t5, 272(a0)
ld t6, 280(a0)
ld a0, 112(a0)
sret /*sret返回*/
为什么专门有这样一个结构用特殊的一页来存储或者说为什么不直接存储在stack中?
riscv在qemu virtborad的实现中只有一个SP寄存器,因此三个异常等级是共用这一个SP寄存器的,在user阶段的异常涉及到异常等级的上升下降,每个异常等级都会使用到不同的stack,也就是说会更换SP寄存器中的值。如果不涉及到异常等级的改变,例如在kernel的运行中出现异常,trapframe就是直接存储在stack当中的:
/*kernelvec是内核空间中发生异常时的异常入口*/
kernelvec:
addi sp, sp, -256 /*make room to save registers*/
sd ra, 0(sp) /*save the registers*/
sd sp, 8(sp)
sd gp, 16(sp)
sd tp, 24(sp)
sd t0, 32(sp)
...
call kerneltrap /*trap handler in c*/
...
ld t4, 224(sp) /*restore the registers*/
ld t5, 232(sp)
ld t6, 240(sp)
addi sp, sp, 256
sret /*return to whatever we were doing in the kernel*/
所以trapframe肯定是需要的,因为trapframe是用来恢复异常之前的CPU状态的,但是trapframe不一定要像RISCV当中一样存储在单独的一页中,他也有可能存储在stack中。
在ARMv8中,每个异常等级都有自己的stack,因此我选择将trapframe直接存储在内核栈当中。
问题1:切换进程的定时器1s一次的时候,进程切换正常,但是提高频率之后trap,且有几率trap错位置(在el1却进入了el0的trap函数,甚至elr=0x01)?排查发现trapframe栈帧有问题设置短了。
问题2:程序在内核和用户空间执行时定时器中断都有可能发生,在内核空间切换trap?内核的切换必须在第一次用户切换之后,不然会加载空的context,设置标志位暂时解决。
4. 用户内核切换
用户空间内核空间的切换实际上就是依赖异常的进入和退出完成的,用户空间和内核空间的切换主要出现在两个时候:
- syscall
- interrupt
5. 上下文切换
上下文切换都发生在内核空间也是两个时候:
- 进程的内核部分切换上下文回到scheduler进程的状态
- scheduler进程切换上下文去到新进程的内核状态
7. 文件系统
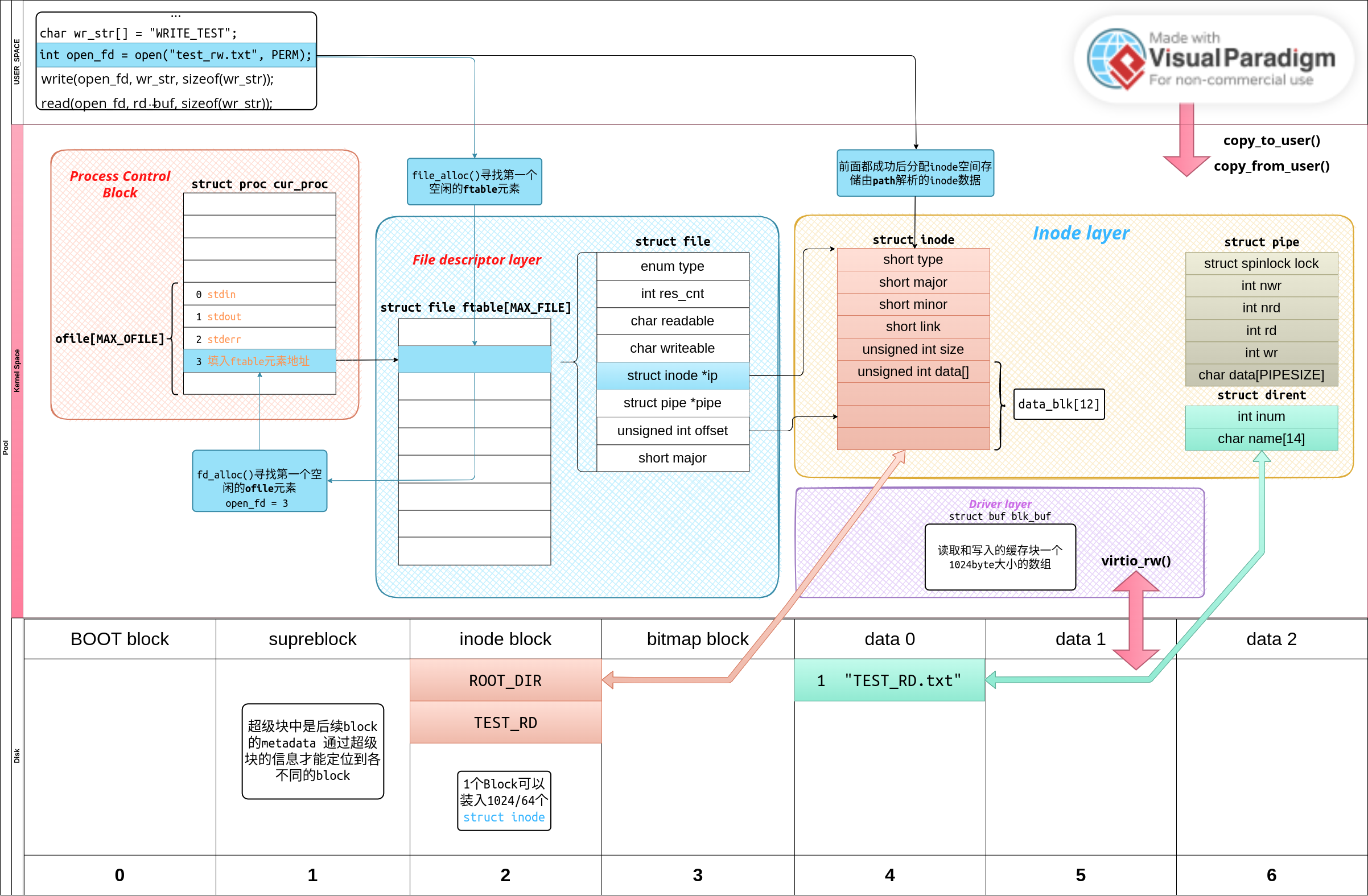
1. 硬件驱动
1. SDMMC
- sdmmc驱动
2. SPI
SPI驱动一定要拉低片选才能通信
问题:发送cmd0之后一直返回0xff?
发送完cmd的6个byte之后不能马上进行读取操作,需要再发送一次或者多次0xff等待sd卡响应。sd卡每次发送命令之前最好先发送一个0xff
问题:读写块不对,只有0正常其他块错误?
读写命令SDHC卡只需要块号就行了 不需要转化成字节地址
- 使用DMA pl330
3. LRU磁盘缓存
使用双向链表完成,头尾各有一个哨兵节点,哈希表暂时没有实现,缓存容量是10个想把几万个blk映射进来不好完成。采用遍历的方式寻找缓存中是否有需要的节点。
struct node
{
int blk_num;
int key;
struct buf data; //存放块数据
struct node *nxt;
struct node *pre;
};
struct LRU_cache
{
int capacity;
int size_cnt;
struct node *head;
struct node *tail;
struct node **hush; //哈希表存储键值对
};

2.调试
#读取sd卡中的前5个blk 每个blk大小512byte 用hexdump打印 -C显示字符
sudo dd if=/dev/sdb bs=512 count=5 | hexdump -C
#向sd卡写入文件mydisk.img 每个blk大小512byte seek=0跳过0个blk
sudo dd if=mydisk.img of=/dev/sdb bs=512 seek=0
8. 具体系统调用实现
1. fork()
2. exec()
Linux中的exec系统调用具体有几个,参数的传递有区别:
- l: list
- v: vector(array)
- p: path
- e: environment
动态链接
加载静态链接的程序很简单,读取到程序内容之后复制并跳转到entry就可以了。动态链接的程序不一样,动态链接会首先加载.interp中指定的动态连接器
3. open()
sys_open()只返回一个fd号,根据这个fd号可以找到struct file,struct file当中存有指向缓存在RAM中的inode的指针,这样就确定了打开的文件。
//用户使用open函数
open("./example.txt", O_RDONLY)
open的系统调用涉及到用户空间往内核空间传参,如果是一个值比如第二个O_RDONLY比较好理解,直接在trapframe中按照顺序找到寄存器的值就行了。假如不是一个值而是类似字符串这样的,我们再去查找寄存器只能找到一个用户空间的地址。内核需要将这个用户空间的地址转换成实际的内核空间中的虚拟地址。
1. copy_from_user()
copy_from_user寻找地址主要有三步:
//根据用户空间的地址va来寻找实际的物理地址pa所在的pte
pte = walk(user_pagetable, va);
//pte中有标志位需要去除
pa = pte & MASK;
//pte中存储的是绝对的物理地址,但是内核空间一般都在高地址,有一定偏移pa_to_va(pa)是加上偏移
pa = pa_to_va(pa);
实际上页表是最小4k对其的,我们查询的时候会将用户空间的va向下0x1000取整查询,查询到之后再找回去取整前的位置
4. read()
5. write()
6. mmap()
mmap()用于给用户空间添加新的映射
9. 用户程序
在0号程序运行起来会呼叫init程序一般是一个shell存储在ROM上,如何编译并且运行这个用户程序?
1. readelf
10. 调度器(Scheduler)
时间片轮转—>O(n)—>O(1)—>CFS
11. 多核
1. mpidr_el1
2. 锁
1. MUTEX
while(!try_lock())
{
sleep();
}
互斥锁得不到会睡眠,比如wfe进入低功耗
2. SPINLOCK
while(!try_lock())
{}
spinlock会不断尝试及
6. 更多
#使用find工具查找可能的文件
find /home/user/documents -type f -name "*.txt"
minicom 默认似乎是不开启line warp 这样超出终端也不会自动换行